After reading the chapters and completing exercises in Unit 3, the reader will be able to:
Good quality safety data are the core of any successful effort to improve road safety. Local, State, and Federal agencies use crash data as well as roadway, vehicle, driver history, emergency response, hospital, and enforcement data to improve road safety. All of these data sources can be used, in isolation or jointly, to produce projects, programs, and guide policies that reduce injuries and save lives. These types of data are collectively categorized as safety data in this book.
Safety professionals in many disciplines—highway design, transportation planning, operations, road maintenance, law enforcement, education, emergency response services, policy makers, infrastructure program management, road safety management, and public health—use safety data to identify problem areas, select countermeasures, and monitor countermeasure impact.
Road safety management and project development has become increasingly data-driven and evidence-based. This approach to road safety emphasizes safety performance (i.e., number of crashes), rather than solely adhering to engineering standards, personal experience, beliefs, and intuition. For example, in the past, road improvements were considered “safe” if the improvements met the standards contained in the Manual on Uniform Traffic Control Devices (MUTCD) and A Policy on Geometric Design of Highway and Streets, also known as the Green Book1 2. However, most of these standards are engineering based (i.e., nominal safety as discussed in Unit 1), and were not necessarily based on an evaluation of actual road safety performance. Presently, transportation professionals use safety data (such as crash data, road characteristics, and traffic volume) to evaluate road safety performance and inform their decisions. This substantive approach challenges professionals to quantify the expected consequences and outcomes of safety strategies in real measurements, such as the expected number of crashes, injuries, and fatalities.
The selection of road safety measures and treatments can benefit from an understanding of the intricacies and limitations of safety data. This unit presents many kinds of safety data, explores the current process used to collect data, and discusses the impact that these processes have on data quality (i.e., accuracy and reliability). The unit also discusses ways to improve data quality and analysis.
The concepts of nominal and substantive safety were first introduced in Unit 1 of this textbook. Nominal safety refers to whether or not a design (or design element) meets minimum design criteria based on national or State standards and guidance documents, such as the AASHTO Green Book or the MUTCD. Substantive safety refers to the actual safety performance, such as expected number of collisions by type and severity on a road.
The contrast of these concepts is directly linked to this discussion of safety data. To determine if a road is nominally safe we do not need safety data; we only need to know if all design standards were followed. However, we need high quality safety data and data analysis to determine if a road is substantively safe. Typically, the analysis includes estimating the expected number of crashes and comparing it against the road’s actual safety performance. More information on safety analysis is presented in Unit 4, Solving Safety Problems.
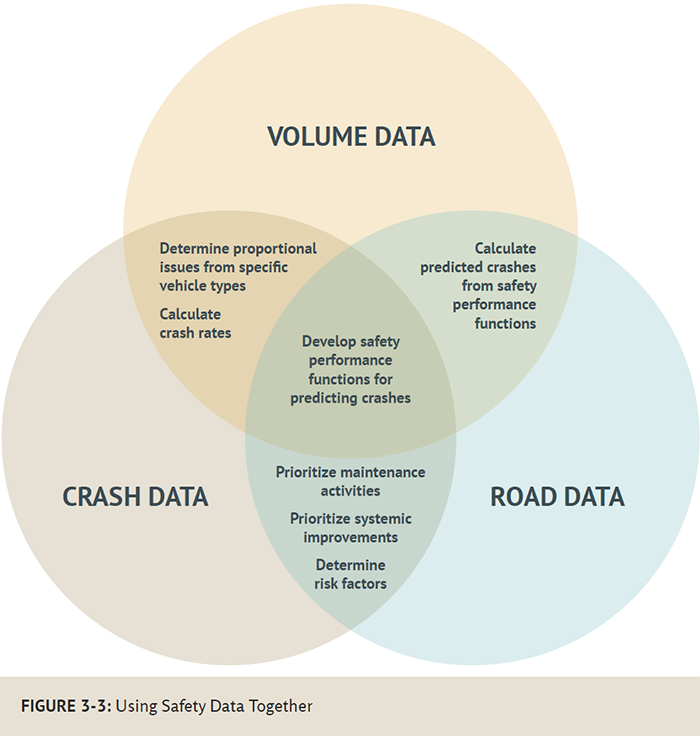
Data are integral to safety decision making, both in prioritizing investments and in identifying analyzing the most effective techniques and interventions. The more comprehensive and accurate the data, the better the resulting decisions. Understanding contributing factors to crashes and how best to implement potential countermeasures is complex, and it may involve a variety of agencies and historical data challenges. Because of this complexity, both accurate data and high quality data analysis is necessary for road safety management. A great database is only as useful as the analysis and application of that data. Table 3-1 explores the relationship between data quality and data analysis quality and shows why agencies should strive to improve both of these areas.

Table 3-1: Data and Analysis Quality Comparison
Crash data analysis using quantifiable metrics and scientifically defensible methods can help decision makers improve road safety by reducing more injuries and saving more lives at a lower cost. Accurate crash data help determine crash and severity trends, such as increases or decreases in certain types of crashes. Data also help safety professionals pinpoint high crash locations and identify highrisk users, such as younger drivers, older drivers, impaired drivers, and motorcyclists. Examining the characteristics of crashes allows road safety professionals to identify contributing crash factors related to roadway environment, design, or behavioral adaptations. This type of analysis will lead to a more effective selection of countermeasures that will reduce future crash occurrences or crash severity. Planners and engineers can use crash data to show quantitative information to decision makers on how specific planning guidance, design proposals, or engineering countermeasures can save lives.
Safety professionals could seek to improve safety by relying merely on their gut judgment. The results of such an approach, however, would be quite unreliable. As shown in Table 3-1, safety professionals can improve their decision making process by using high quality data together with robust analysis processes. This unit will focus on the data itself. The use of the data in safety management is presented and discussed in Unit 4.
Good quality safety data and analysis are the keys to identifying real safety issues on roads and evaluating the best methods for improving safety. The following chapters provide an overview of different types of safety data and of ways in which agencies can improve the quality of their data.
Chicago DOT completed a comprehensive pedestrian crash analysis in 2011 to inform the citywide Chicago Pedestrian Plan. This analysis evaluated various crash types, contributing environmental factors, and different age groups using the Illinois Department of Transportation crash data files. The findings present crash density citywide, by ward, and around schools. The data also highlighted key crash conditions and served as a benchmark for measuring the City of Chicago’s road safety goals.
Reference: City of Chicago 2011 Pedestrian Crash Analysis, Summary Report, Chicago Department of Transportation, Accessed September 2016 at https://www.chicago.gov/city/en/depts/cdot/supp_info/2011_pedestrian_crashanalysis.html
As highway safety analysis methods continue to evolve, it is equally important to focus on quality data to conduct these safety analyses. Transportation agencies can and should incorporate road characteristics, traffic volume, and enforcement and citation data, and other information into their safety analysis processes. This will enable them to better identify safety problems and prescribe solutions that improve safety and make more efficient use of safety funds.
Single sources of safety data also do not give a complete picture of the safety risks on our roads. For example, using crash data by itself leaves safety practitioners with purely reactive approaches—identifying locations where crashes have already happened. By combining crash data with other types of data, more details begin to emerge. For example, by combining crash data and detailed road inventory information, safety practitioners can develop a more in-depth understanding of the road attributes that contribute to crash risk. This will allow them to adopt a proactive approach, seeking out those factors associated with a high risk of crashes and addressing sites that share those “elements” before a crash occurs.
Physical features of the road such as travel lanes, shoulder width, pavement condition, and roadside characteristics
Crash, roadway, and traffic data should be integrated or combined using common or “linking” reference systems, such as mileposts or geospatial position. These data should also have the ability to be linked to the State’s other road safety databases, including citation data or injury surveillance systems. Additionally, commercial motor vehicle data could also be linked based upon common data elements involved in crashes and inspections.
Not all types of safety data are available or used by all practitioners. Safety data exist in distinct databases that are maintained by different agencies and often are accessible only to those agencies. One role for safety professionals is to bring together safety databases and analyze them using logical and statistically robust processes.
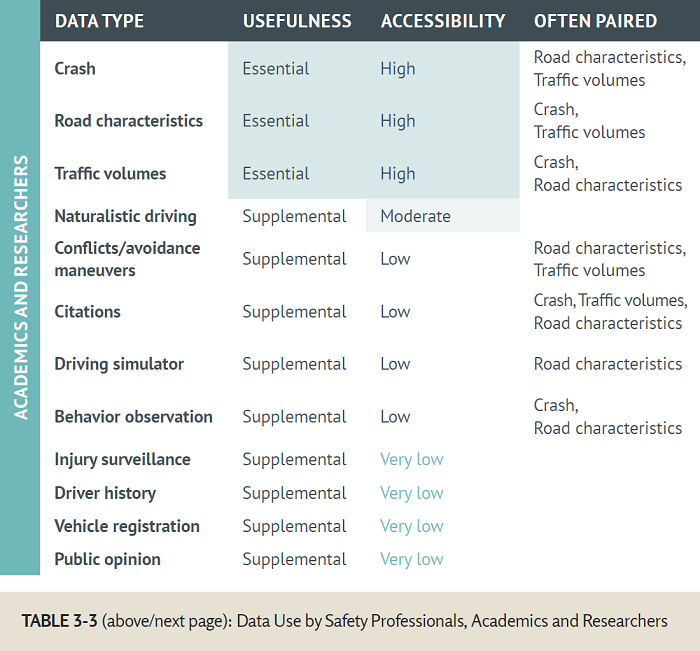
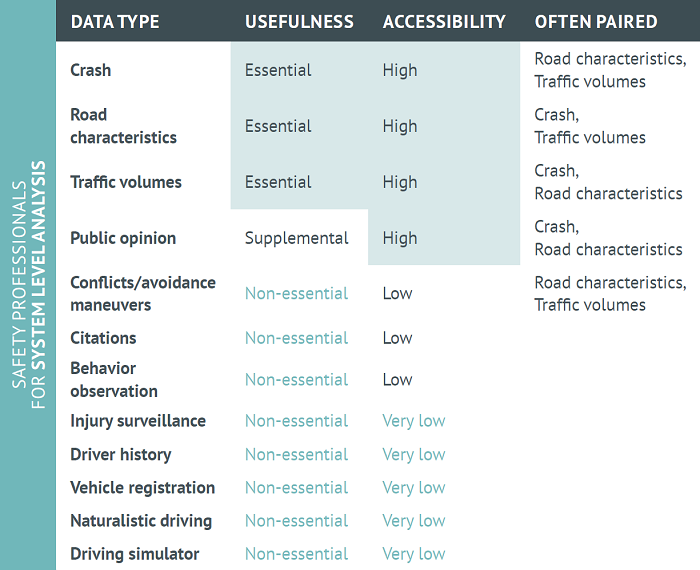
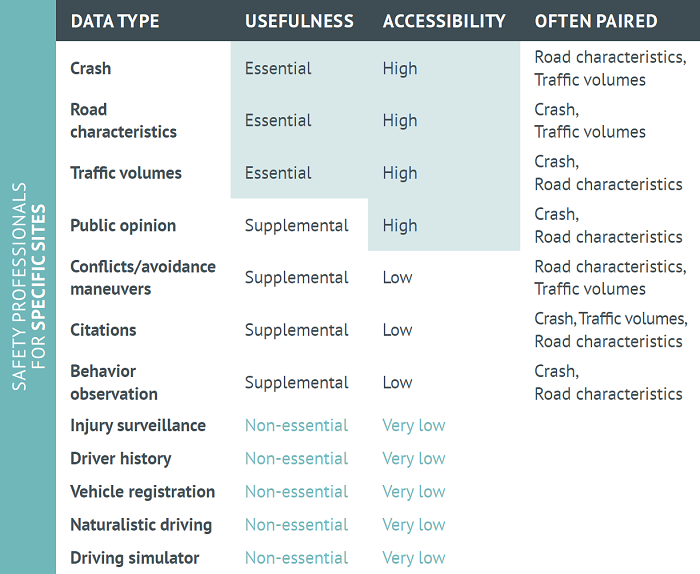
Safety data can be categorized into two groups based on criteria of core data needs for safety evaluations, data availability, accuracy, and usefulness to safety practitioners and researchers. Some safety data are used often and are critical to safety analysis for many agencies. Other safety data are used less often but can be supplemental to specific safety analyses. This chapter provides general information on safety data in these two groups:
Crash data is the most widely used type of safety data, and it is essential in road safety analysis. Crashes are currently viewed as the most objective and reliable measurements of road safety. However, there are challenges with crash data, such as human error in reporting, unreported crashes, and the length of time it often takes for crashes to be entered into a database. Crash data is also the primary measure of effectiveness for safety efforts, since the goal is to decrease crash occurrences and lower the severity of crashes that do occur. Crash records typically provide details on events leading to the crash, vehicles, and people involved in crashes, as well as the consequences of crashes, such as fatalities, injuries, property damage, and citations.
Crash data collection begins when a State highway patrol trooper or local police officer arrives at the crash scene. The officer completes a crash report, documenting the specifics of the crash. While the specifics and level of detail of the crash data vary from State to State, in general, the most basic crash data consist of where and when the crash occurred, what type of crash it was, and who was involved. The specific data collected on crashes is determined by State agencies, local government agencies, and often a coalition of law enforcement agencies. The exact data fields and coding differ from State to State. The level of detail in a crash report may also differ by the severity of a crash. For instance, in some States property damage only crashes (PDO) are self-reported and, thus, often have less information than injury crashes, which are reported by law enforcement officers.
States also differ in the threshold of what is required for a crash to be reported. Reporting of crashes can vary by threshold requirements, such as “only injury crashes” or “PDO crashes” over an estimated $2,000 in damage.” These thresholds are unrelated to the number of crashes that are actually occurring on a road, but the reported numbers could look quite different. Changes to the crash reporting thresholds can happen abruptly and may significantly affect the crash data. Consider how the safety of a road, based on reported crashes, would appear in the years before and after a crash reporting threshold change from $1,000 to $4,000. You would expect to see fewer reported crashes after the change, since crashes with damage below $4,000 would no longer be reported, even though there may be no real change in the number of crashes occurring.
After the crash investigation is completed by the officer for the investigating agency, it usually undergoes an internal quality review. Passing the internal review, the crash report is sent to the State crash database. In some cases, the data is transmitted electronically, while in other cases the State agency receives a paper copy of the crash report.
The agency that maintains crash data for the State may be the State department of transportation (DOT), the department of motor vehicles (DMV), or a State law enforcement agency. This agency will in turn make the data available to various other agencies. Federal, State, and local governments, as well as metropolitan planning organizations, advocacy groups, auto and insurance industries, and private consultants request crash data to conduct various transportation planning activities and analysis. The agency maintaining the data may provide raw or filtered datasets to local agencies and to national databases, such as the National Highway Traffic Safety Administration’s (NHTSA’s) Fatality Analysis Reporting Systems (FARS).
The time between the crash occurrence and the availability of the crash data from the State crash database varies and typically depends on the type of crash reporting system and the State and local government capabilities. This time period between crash occurrence and the report’s availability for analysis defines the timeliness of the crash data. While some agencies can provide complete data with a very short turnaround (i.e., less than a month), others take significantly longer (i.e., up to two years) due to backlogs and personnel shortages. Agencies who have the majority of their crashes reported electronically from law enforcement typically have shorter turnarounds on the crash data.
Common data elements for crash data include information on date, location, injury severity, types of vehicles, and characteristics of persons involved. Crash narratives and diagrams are typically found in the original crash reports, though generally not in the crash database. Narratives and diagrams are most useful when the safety professional desires to know the exact location of the crash, such as the particular approach of an intersection.
NHTSA developed the Model Minimum Uniform Crash Criteria (MMUCC) in 1998 as a model set of data elements that should be collected to enable safety professionals to conduct data-driven analyses. States are encouraged to adopt MMUCC standards, though they are not required to match these recommendations. MMUCC, currently in its fourth edition, recommends the crash data elements listed below. Chapter 3.3 presents further information on MMUCC.
Crash details may be available from different sources or systems. State agencies and institutions typically maintain the State crash database. These include State departments of transportation, departments of motor vehicles, departments of public safety, or in some cases, State universities under contract to a specific department. Local agencies, such as cities or metropolitan planning organizations, may also maintain their own crash databases within local record management systems. These local systems are most frequently housed by the local police, public works, or transportation departments.
Crash data serve as the primary observable measure of safety (or lack thereof) on the road. Transportation professionals can use crash data to analyze a single crash, a specific site, an entire corridor, or a large area, such as in regional or Statewide planning. Crash data can be used to provide guidance to transportation decision makers and to guide the formation of safety legislation.
In transportation departments, other data elements frequently used along with crash data include road characteristics and traffic volume data. For example, by combining road characteristics with crash data, safety professionals are able to identify road elements that may lead to higher frequency or injury severity of crashes, and therefore develop a systemic approach to reduce that crash risk at many of the locations that have those risk elements. Using traffic volume, agencies can calculate crash rates (e.g., crashes per road vehicle) to better identify locations requiring safety improvements.
Crash rate calculation (crashes per amount of traffic) is a simplistic measure that may be useful when comparing sites with similar characteristics and traffic volumes. However, the relationship between crashes and volume is not linear and can therefore lead to wrong conclusions if that assumption is made when considering volume increases on a road or comparing roads of different types. Unit 4 discusses how an analyst can use safety performance functions to avoid this error.
Some of the most common issues found in crash reporting include incomplete data (for example a driver’s blood alcohol content is often missing), delays in entering the data into databases, inaccurate crash locations, and wrongly assigned fault and wrong choice of crash type. Some of these issues can be fixed by training police officers and those who enter the data into the database, as well as by using technology checks in data collection. Agencies should periodically conduct independent quality checks on the accuracy and reliability of their data.
The Oregon DOT identified pedestrian and bicycle crashes as one of its primary focus areas for infrastructure funding. While pedestrians and bicyclists account for more than 15% of all traffic fatalities statewide, the locations of serious injuries and fatalities appear to be random. Therefore, in 2013, ODOT set out to develop a program that focuses the limited available funding for infrastructure countermeasures on locations with the greatest crash potential. In order to identify these higher-risk locations, ODOT is working to discover behavioral patterns and road conditions that lead to pedestrian and bicycle crashes. While a promising approach, this analysis is constrained by the limited availability of road information (e.g., bicyclist and pedestrian volumes, the presence of crosswalks, turn lanes, driveway activity, and sight distances). While the lack of these data does not preclude such an analysis, it does reduce the certainty of the findings. An additional benefit from this effort is that it has helped ODOT identify current data deficiencies which ODOT is currently working to fix.
Reference: Pedestrian and Bicycle Safety Implementation Plan, Oregon Department of Transportation, February 2014. Accessed September 2016 at https://www.oregon.gov/ODOT/HWY/TRAFFIC-ROADWAY/docs/pdf/13452_report_final_partsA+B.pdf- this content is no longer available
Traffic volume data indicates how many road users travel on a road or through an intersection. The most prevalent type of volume data is a count of daily use by motorized vehicle traffic. This type of traffic volume data can be measured in many ways depending on the intended use. Volume measurements include:
AADT is the average number of vehicles passing through a segment from both directions of the mainline route for all days of a specified year. As AADT requires continuous year-round counting, these data are often unavailable for many road segments. In these cases, ADT is used to estimate AADT by using shorter duration counts of that road and then adjusting those volumes by daily and seasonal factors. Other data used for crash analysis include turning movement counts and TEV at intersections and VMT on a road segment, which is a measure of segment length and traffic volume. VMT are useful for highway planning and management, and a common measure of road use. Along with other data, VMT is often used to estimate congestion, air quality, and expected gas tax revenues, and can serve as a proxy for the level of a region’s economic activity. Volume data is also occasionally collected for bicyclists and pedestrians at road segments and crossing locations.
Volume data can be collected automatically or manually. Vehicle volume data is typically collected using automated counters, such as magnetic induction loops, pneumatic tube counters, microwave, radar, or video detection. These automated counters can also be configured to classify vehicles and produce counts by vehicle type (e.g., trucks, single passenger vehicles, etc.). For shorter durations or occasional counts, transportation agencies use manual traffic counts performed by observers, either in the field or through video cameras. Manual counting is also used often for bicyclist or pedestrian counts, although there are a number of additional technologies, such as infrared beams, that can be used to collect non-motorized volume data. These manual counts can range in length from one-hour counts to full-day counts, depending on the agency’s needs and practices. Fitness tracking apps may also provide additional information to jurisdictions regarding where bicyclist and pedestrian activity is occurring. Some care is needed when using these data due to the self-selection bias present from users having to opt-in to the tracking and only using for specific types of activities (e.g., fitness cycling rather than commuting).
Short term traffic counts are typically collected at a location for a 12-, 18-, or 24-hour period. Average Daily Traffic (ADT) is the count of traffic calculated to reflect the 24-hour (daily) volume of the date it was collected. The Annual Average Daily Traffic (AADT) is calculated for an entire year from the ADT by adjusting that simple average traffic volume to take into account the different travel patterns that occur during short duration count periods. For example, a summer traffic count taken in a beach vacation town would need to be adjusted downward to reflect the average traffic volume for the year, since traffic would be much higher in the summertime.
Each State has its own traffic data collection needs, priorities, budget, and geographic and organizational constraints. These differences cause agencies to select different equipment for data collection, use different data collection plans, and emphasize different data reporting outputs. The FHWA Traffic Monitoring Guide (TMG) highlights best practices and provides guidance to highway agencies in traffic volume data collection, analysis, and reporting.3 The TMG presents recommendations to improve and advance current programs with a view towards the future of traffic monitoring. Traffic data is used to assess current and past performance and to predict future performance. Some States are utilizing traffic data from intelligent transportation systems (ITS) to support coordination of planning and operations functions at the Federal and State levels.
Volume data must include the counted volume, location, date, and duration of the count. Depending on the method used, the volume data may also contain information on vehicle classification, speed, or weight; lane position; weather; and directional factors. From these data, transportation professionals can calculate the average number of vehicles that traveled each segment of road and daily vehicle miles traveled for specific groups of facilities, vehicle types, and vehicle speeds.
Many of the types of data presented in this chapter can be stored in a spatial format and displayed in a GIS. GIS is a particularly powerful tool designed to store, manipulate, analyze, and visualize data that is linked to a location. This makes it valuable to highway safety practitioners who can use a common referencing system for much of their highway data and link it together in GIS. For example, a single GIS database can contain road attributes, such as number of lanes, pavement condition, and lighting; crash information; and traffic volumes. This information can then be used to analyze crash hotspots and trends, such as multi-vehicle crashes in the vicinity of signalized intersections.
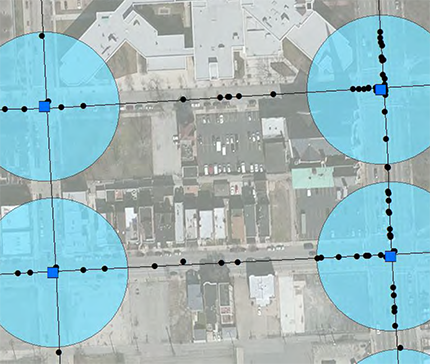
This GIS map displays signalized intersections as squares and crashes as dots and allows the analyst to easily identify crashes occurring within 150 feet of a signalized intersection (denoted by circular areas around each intersection).
State highway agencies collect and maintain traffic volume data for State-controlled roads. These data are shared with the U.S. Department of Transportation in order to monitor road usage and safety trends. Local jurisdictions also collect and maintain traffic volume data; the scope, consistency, and quality of these data varies by jurisdiction.
Agencies use volume data to support activities in design, maintenance, operations, safety, environmental analysis, finance, engineering, economics, and performance management. For instance, total traffic volume estimates or forecasts on a section of road are used to generate State and nationwide estimates of total distance traveled. Annual traffic volumes are also essential in network screening, diagnosis, and the selection of countermeasures (see further presentation of these processes in Unit 4). When selecting appropriate crash modification factors (CMFs) to estimate the benefit of potential countermeasures, a safety practitioner must use traffic volumes to confirm that the CMFs are suitable for the site in consideration.
Other data elements frequently used with traffic volume data in safety applications include road characteristic inventories and crash data. For example, an agency that uses traffic volume and crashes together can identify sites with highest potential for safety improvements and target specific crash types. This allows them to better identify and prioritize locations for safety improvements.
One of the biggest challenges in collecting accurate volume data is implementing a quality assurance process to ensure that counts are accurately recorded. Traffic volume for most roads is also based on sampling, which leads to estimates of volume on much of the road. As technology continues to develop and become more prevalent on our roads and in our vehicles, the accuracy will improve considerably. Additionally, pedestrian and bicyclist counts are more susceptible to higher variability due to their lower volumes; thus, longer count durations and additional locations are required for accurate data applications.
Road characteristics data is also referred to as road inventory data. The most basic road characteristics data typically includes road name or route number, road classification, location coordinates, number of lanes, lane width, shoulder width, and median type. Intersection characteristics typically include road names, area type, location coordinates, traffic control, and lane configurations. The collection of these data elements supports an enhanced safety analysis and investment decision making when combined with other datasets, such as crash information.
Road characteristics data can be collected through several methods including photo or video logs, field surveys, aerial surveys, integrated GIS and global positioning systems (GPS) mapping, and vehicle-mounted Light Detection and Ranging (LIDAR) technology. Some States find it more cost effective to purchase these data from third party providers.
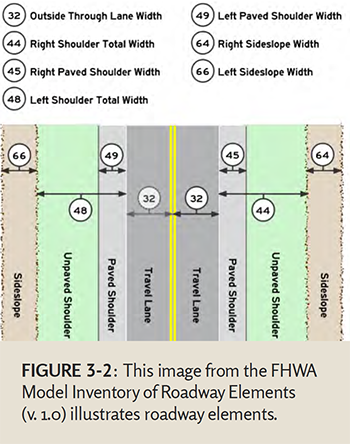
Transportation agencies typically collect those road characteristics that they need or can be collected based on the available funds. Road characteristics are collected for many different purposes, such as road maintenance and improvement projects. Given that States have different priorities and funding structures, the elements of road characteristics data is not the same from State to State or among local agencies.
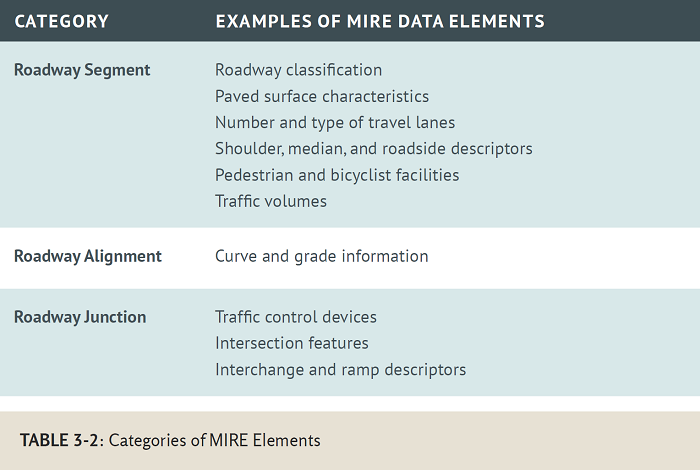
To provide guidance on road characteristics that are the most needed for safety analysis, the FHWA developed the Model Inventory of Roadway Elements (MIRE). MIRE provides a recommended (but not required) list of road characteristics elements specifically for safety analysis. The elements are divided into the categories shown in Table 3-2. Chapter 9 presents further information on MIRE.
Road characteristics data are collected at both the local and Statewide levels. At the local level, having data on details, such as traffic control devices, sidewalks, or the number of travel lanes, can be beneficial for safety evaluations and safety project prioritization. These data are maintained by the city or by a higher level agency such as a MPO.
State road characteristics data include physical road attributes, traffic control devices, rail grade crossings, and structures, such as bridges and tunnels. Each State highway agency, some local transportation and public works departments, and regional planning agencies collect and maintain road characteristics data. In addition, most States also have supplemental inventory data for bridges as part of the National Bridge Inventory and railroad grade crossings as part of the Federal Railroad Administration’s Railroad Grade Crossing Inventory. These databases usually can be linked to the Statewide road inventory.
Road safety professionals can use road characteristics data to access data about the physical characteristics of crash sites or other priority sites. Road characteristics data is essential for network screening, development or calibration of crash prediction models, and related applications. These data are also valuable on the large scale level to estimate where crashes are expected to occur on the system.
Road characteristics data can be linked with crash and volume data to improve safety analysis and problem identification. Combining datasets in this way allows safety professionals to identify areas with a high potential for safety improvements (by means of a network screening process) and identify appropriate countermeasures. However, the road characteristics data must share a common reference system with the crash and volume data in order to link them together. The most common methods of linking road data with crash or volume data use a linear referencing system, such as routes and mileposts, or a spatial referencing system, where all files share the same coordinate system.
Collecting accurate road characteristics data can be a time-consuming and expensive process. Data collection that is done only for part of a road network results in gaps in inventories of road features such as the location of guardrails, shoulder widths, and rumble strips. Transportation agencies are continually looking for newer technologies to streamline the collection of this detailed data. Also, it is more common for road characteristics data to be fuller and more detailed for State system roads compared to local roads, since local agencies typically have less funding, fewer staff, and less general prioritization for collecting road characteristics data.

In addition to the critical transportation safety datasets (crashes, road characteristics, and traffic volume), there are many other datasets that can be used and combined to conduct additional types of evaluations on the effectiveness of programs, human behaviors and safe decision making, and public opinions.
Observing conflicts between road users, avoidance maneuvers, such as swerving or hard braking, and other interactions, such as failures to yield can provide valuable information on road safety. These other measures of safety are referred to as surrogate measures. They occur more frequently than actual crashes and therefore enable agencies to identify safety risks more quickly and in a proactive manner (i.e., before the crash occurs). However, by their nature of being surrogates, there is potential for inaccuracy in determining which types of conflicts are good indicators of crashes.
Surrogate safety data is collected by in-field observers or through recordings that capture the behaviors and interactions of road users. These recordings can be made through stationary cameras or dashboard-mounted video cameras.
Increasingly, researchers are using programs to automatically identify potential events. This eliminates the need to scan visually through the entire video.
Many off-roadway crashes are not reported by law enforcement and are thus missed when conducting safety evaluations using police crash reports. One group that is particularly affected by this lack of data is young children injured by passenger vehicles in driveways and parking lots. This lack of information provides safety professionals with little knowledge about crash risk factors and actual incident rates that could be used to allocate resources and promote safety interventions and good design and behaviors. A 2010 study (Rice et al.) in California used records from eight trauma centers to identify the frequency and characteristics of these crashes. This study highlighted the inconsistencies with external cause-of-injury codes used by emergency departments, but suggests that there is value to surveillance of off-roadway pedestrian injuries at trauma centers as a way of identifying incidents that are not captured by other data sources.
Reference: Rice TM, Trent RB, Bernacki K, Rice JK, Lovette B, Hoover E, Fennell J, Aistrich, AZ, Wiltsek D, Corman E, Anderson CL, Sherck J. (2012). Trauma center-based surveillance of nontraffic pedestrian injury among California children. Western Journal of Emergency Medicine; 13.2.
Observing interactions between road users can provide valuable information on the safety effect of certain road elements, such as signals or signs, and help identify the probability of crashes under different conditions. If a reliable relationship between the observations and crashes is known, such studies may also provide insights into the potential for safety issues between road users, such as between vehicle drivers and pedestrians.
However, one of the biggest challenges for using observations of road user interactions is that they are surrogate measures of safety. To date, we lack good research that would quantitatively equate surrogate measures of safety to crash data. If such relationships were known, safety professionals could conduct evaluations with a large number of surrogate measures in a relatively short period of time. This contrasts with the need to wait for years for sufficient crash data to support a good analysis.
Injury surveillance systems (ISS) typically provide data on emergency medical systems (EMS), hospital emergency departments, hospital admissions/discharges, trauma registry, and long-term rehabilitation. This information is used to track injury causes, severity, costs, and outcomes. Although an injury associated with a traffic crash is only one type of injury in these medical systems, traffic crash injuries can be a useful source of data in bridging the gap between traditional traffic safety and public health issues. Hospital records are also often the only source of information on bicycle and pedestrian crashes that are not recorded by the police, such as those that occur in non-roadway locations like parking lots and driveways.
Hospitals often use the external cause of injury classifications to code causes of patient injuries, including those from traffic crashes. These data can provide a description of injury severity, type of crash (e.g., motor vehicle passenger, bicyclist), and, in some cases, the location of incident. However, the data is often incomplete or non-specific. In order to provide a more comprehensive understanding of motor vehicle crash outcomes, NHTSA developed the Crash Outcome Data Evaluation System (CODES), which links crash, vehicle, and behavior characteristics to their specific medical and financial outcomes. Hospital injury data most often includes date, injury severity, cause, and demographic information. Personal identifying information is not included.
Hospital data can be used by a variety of governmental and non-governmental agencies to investigate the causes of injuries. Based on this analysis, the agencies can develop a safety campaign to reduce injuries to particular demographics. It can also be used to identify the full magnitude of crashes for a specific user group or demographic that is not recorded or reported by law enforcement. For example, hospital data can help safety professionals better understand the number of bicyclist crashes, since many bicycle-related crashes are not reported to law enforcement.
Hospital data are often difficult to use for those who administer roads, primarily the State DOT. The data is time consuming to acquire and may not contain complete data. Additionally, since there are no personal identifiers relating hospital injury data to specific crash records, the linkage is difficult and is seldom done. For these reasons, State DOTs rarely use these data; it is most often employed by public health researchers. However, there continues to be efforts at both Federal and State levels to develop better ways to integrate injury surveillance and emergency medical systems data with crash data.

Departments of Motor Vehicles (DMVs) maintain driver history data on all licensed drivers in the State. DMVs typically create a driver record when a person enters the State licensing system to obtain a driver’s license or when an unlicensed driver commits a violation or is involved in a crash. State driver history databases interact with the National Driver Register (NDR) and the Commercial Driver License Information Systems (CDLIS) to prevent drivers with a history of at-fault crashes or inordinate number of citations from obtaining multiple or subsequent licenses.
The driver history data contain information such as:
One challenge with using these data is that they are almost never shared outside a DMV. State or local DOTs do not have access to these data while developing their HSIPs (or conducting location specific safety studies). Sharing driver history data nationally is limited and could be improved by creating inter-agency data sharing partnerships that address privacy concerns and allow State DOTs to work with the data.
Vehicle registration data includes information about registered vehicles in a State and is also typically maintained by the DMV. Vehicle registration systems may also contain information regarding commercial vehicles and carriers registered in a particular State and licensed to travel in other States. These data can provide information on the vehicle population within a State or county to be used in large scale safety analysis. These data can also help identify owners in the event of a crash or traffic violation.
Typical vehicle registration data may include owner information, license plate number, vehicle make, model, and year of manufacture, body type, vehicle identification number, and miles traveled. Common data for commercial vehicles may include U.S. Department of Transportation (DOT) number, carrier information, and inspection or out-of-service information.
Citation data refers to data on individual drivers that records any illegal actions that were cited by a law enforcement officer. It includes traffic violations, such as reckless driving, driving under the influence, and not carrying adequate car insurance; traffic crashes; driver’s license suspensions, revocations, and cancellations; and failures to appear in court. The data can also include the traffic infractions that have been adjudicated by the courts.
These data are helpful in identifying and tracking those individuals with a higher potential for unsafe driving behaviors. In an attempt to control crash occurrences, States may monitor high-risk drivers by reviewing their driver history records, paying particular attention to driver citations. Ideally, States track a citation from the time it is issued by a law enforcement officer through its disposition in a court of law. Citation information tracked and linked to driver history files enable States to screen drivers with a history of frequent citations for actions known to increase crash risk. States have found citation tracking systems useful in detecting repeat traffic offenders prior to conviction. It can also be used to track the behavior of particular law enforcement agencies and the courts with respect to dismissals and plea bargains. Many law enforcement agencies use citations as a method of tracking and measuring the effectiveness of enforcement efforts.
Some constraints exist with the use of citation and enforcement data to help prevent crashes. Some States have difficulty in maintaining accurate citation information because local jurisdictions may collect different data elements from varying citation forms. Obtaining and managing judicial information is also a challenge because of the various levels of court administration and jurisdiction. Unfortunately, in some States judges do not have access to the offender’s driver history at the time of sentencing, so many offenders escape the stricter penalties sanctioned for repeat offenses. In addition, the traffic safety community often lacks access to adjudication information due to privacy concerns.
The largest naturalistic study in the United States to date is the second Strategic Highway Research Program (SHRP2), which included over 3,400 drivers participating in the study. SHRP2 data includes over 5,400,000 individual trips and over 36,000 crash, near crash, and baseline driving events. FHWA provides more information on SHRP2 at https://www.fhwa.dot.gov/goshrp2.
Naturalistic driving data are driver behavior data collected during actual driving trips through technology placed in the vehicle. This technology typically includes video camera views of the driver, speed and vehicle motion sensors, and location tracking equipment. Data such as video might be collected on a continuous basis, or only after certain events like hard braking. Using data collected by this equipment, researchers are able to gather information on the underlying causes of crashes by observing drivers in a natural driving situation. Frequently collected data include road environment information, such as weather; driver information, such as eye movements; and information on vehicle movement including location on the road, acceleration, deceleration, and speed.
These data are used to evaluate how drivers interact with and react to the road, other road users, and other environmental features. Driver observation is used to understand fundamental issues of driver behavior and to develop improved safety countermeasures. The data are primarily used in research studies on a variety of topics. The data from the SHRP2 program have been used to study safety issues including prevention of road departures, driver reaction to posted speed limits, and driver response to curves in the road, in addition to many non-safety-related topics.
A challenge with collecting a large amount of naturalistic data is the high cost of recruiting participants, instrumenting vehicles, and reducing and analyzing the data. The process of coding (observing) the behaviors of the driver while driving is time-consuming and is typically conducted on a frame-by-frame basis, leading to expensive data collection and lengthy study periods. The data are highly private (i.e., contains videos of driver faces), and therefore are typically difficult to access or distribute. Despite these challenges, naturalistic driving data provides a unique and extremely insightful look at fundamental issues of road safety.
Due to the high cost of naturalistic driving studies and the rarity of traffic crashes, driving simulators are often used to efficiently and safely evaluate driver behavior under different conditions. Researchers are able to study many different conditions and complex environments without exposing drivers to danger through replicating a wide range of road, traffic, and environmental conditions, as well as driver behaviors such as distractions, impairment, and fatigue. New types of road designs can be guided by the use of simulators, particularly complex features, such as urban highway interchanges.
Simulators can also be used for driver education to teach people about the effects of driver distractions or to prepare young drivers for different conditions before they encounter them on the road. Truck simulators are used to replicate the driving environment for different types of commercial trucks and used to safely train new drivers.

Feedback from the general public can be a useful source of information for safety professionals. Safety professionals can use information on road safety issues and concerns from the public to identify specific locations or types of conditions where people have real or perceived traffic safety concerns.
There are many different ways to collect this information, such as a phone-based survey, web-based tools (pins on maps or online forms), meetings, or intercept surveys. Common data collected are the type of concern, location, and type of mode (i.e., walking, bicycling, transit user, or driving).
These data are typically collected at the local level, frequently as part of a transportation planning process or as a collaborative effort with law enforcement. Bringing residents and police officers to join the road safety audit teams or diagnosis teams during their field visits is also a beneficial way to learn about the experiences of the road users in the study area.
These data may provide valuable insights about what the travelling public perceives as dangerous; however, it may be a biased sample based on those who self-select to provide the information to the researching agencies. Findings will be subjective as each person perceives a condition based on their individual experiences only. Different persons perceive different issues and recommend different “best” solutions for the same condition. Conclusions based on survey findings should be used with care.
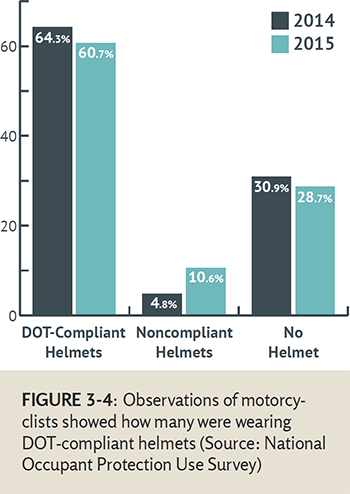
Observational surveys of road user behaviors are an effective method of data collection on information that may otherwise be inaccurately recorded due to self-reporting bias or are difficult to capture through other means. Several examples of data typically recorded using direct observation are the use of mobile devices (texting or calling), right turn on red, safety belt use, motorcycle or bicycle helmet use, and traffic control violations, such as rolling through stop signs.
These data are collected through observing road users on the road. Large scale surveys collecting a high number of observations will provide the most accurate sample of the road user population in the study area. Additionally, robust observation data will cover differing road types and land use characteristics and contain observations at different times of day, week, and season. An example of a large-scale data collection effort is the National Occupant Protection Use Survey conducted annually by NHTSA. In 2013, over 52,000 occupants were observed in nearly 40,000 vehicles. The data, summaries, and evaluations from this program may be viewed on the NHTSA website.4
While many agencies use safety data, most of them have different goals. For example, a city traffic engineer may have a specific scope for identifying and treating specific high priority sites, whereas a safety analyst with a State may be focused on safety at the system level. Moreover, safety researchers and graduate students may be focused on a whole range of safety evaluations that are not intended to be action plans to improve safety at a specific site or system. Each type of data user may have different levels of access to these various types of safety data.
The following tables provide common uses and data needs for these different types of data users.
Additional types of data can also be useful to road safety professionals. These types of data may include:
(e.g., carrier, policy number, expiration date, claims cost)
These data can provide insights into associations between insurance status and safety.
(e.g., population by gender, age, rural/urban, residence, and ethnicity)
These data can be used for normalizing crash data to a state’s general population.
(e.g., surveys, assessments, inspections)
These data can provide feedback on the effectiveness of a new safety program
(e.g., guardrail replacement)
These data may indicate where unreported crashes are occurring.
The previous chapters in this unit have made the case that data are critical when seeking to improve road safety. However, simply having data is not enough. Good decisions require good data. When collecting, recording, maintaining, and analyzing safety data, road safety professionals must focus on the quality of data. Data-driven analysis tools are continually advancing and can help set priorities and select appropriate safety strategies, but the need for quality data to drive these tools is clear. Professionals commonly recognize that data quality can be measured on six criteria—timeliness, accuracy, completeness, uniformity, integration, and accessibility. Each of these criteria are presented in this chapter.
Timeliness is a measure of how quickly an event is available within a data system. State and local agencies can use technologies to automate crash data collection and quickly process police crash reports for analytic use. However, some agencies still rely on traditional methods, such as paper form data collection and manual data entry; these data collection methods can result in significant time lags. Many States, however, are moving closer to real-time data collection methods by using electronic reporting to improve the timeliness of data collection and submission.
Accuracy is a measure of how reliable the data are and whether they correctly represent reality. For example, exact crash location is an important detail for accuracy. A crash occurring at the intersection of First Street and Main Street should be recorded as occurring a that intersection. Accurate data are crucial during the analysis phase to generate road safety statistics and to pinpoint safety problems. Errors may occur at any stage of the data collection process. Common data accuracy errors include:

Technology can and is currently being used to improve accuracy and reduce errors. Automatic internal data quality checks are important for this purpose. These types of checks would determine if two data fields contain possibly conflicting data, and if so, bring it to the attention of the data analyst. An example of conflicting data fields would be a crash type recorded as “rear end” but the crash report says that one car was hit on the “side.”
Completeness is a measure of missing information. It may range from missing data on the individual crash forms to missing information due to unreported crashes.
Unreported crashes, particularly non-injury crashes, present a drawback to crash data analysis. Without knowing about these crashes, we cannot recognize the full magnitude of certain types of crashes (e.g., pedestrian involved crashes). Non-injury crashes, or property damage only (PDO) crashes, involve damage less than a specified threshold (e.g., $1,000); these thresholds vary from State to State. The parties involved in PDO crashes are typically not required to report the crash and often agree to work out the financial damages personally or through their automobile insurance policies. In some States, even when PDOs are reported, they are not always added into the crash database.
In addition to the limitations from absent data due to unreported crashes, fluctuations in the thresholds (i.e., dollar amounts) can make it difficult to compare data from previous years. Unreported PDO crashes are one of many measures of “completeness” that road safety professionals must consider when collecting and analyzing data. A lack of complete data hinders the ability to measure the effectiveness of safety countermeasures (e.g., safety belts, helmets, and red light cameras) or change in crash severity.
The Federal government established the Crash Data Improvement Program (CDIP) to provide states with a means to measure the quality of the information within their crash database. It is intended to provide the states with metrics that can be used to establish measures of where their crash data stand in terms of its timeliness, the accuracy and completeness of the data, the consistency of all reporting agencies reporting the information in the same way, the ability to integrate crash data with other safety databases, and how the state makes the crash data accessible to users. Additionally, CDIP was established to help familiarize the collectors, processors, maintainers, and users with the concepts of data quality and how quality data help to improve safety decisions. CDIP also included a guide that presents information on each data quality characteristic and how to measure them.
Reference: Crash Data Improvement Program, National Highway Traffic Safety Administration, https://www.nhtsa.gov/data/traffic-records
Uniformity is a measure of how consistent information is coded in the data system or how well it meets accepted data standards. Numerous law enforcement agencies within each State, some of which are not the primary users of the crash data, are responsible for crash data collection. The challenge for States is ensuring there is consistency among the various agencies when collecting and reporting crash data. One example of inconsistent or non-uniform data can be the location of a crash. If one agency, for example the State highway patrol, uses GPS to document a crash at one of several entrances (driveways) to a shopping center, but the city police use a linear reference system (e.g., distance from an intersection), there is a potential for inconsistent crash location data.
The Model Minimum Uniform Crash Criteria (MMUCC) is used by States to ensure uniform crash data. MMUCC is an optional guideline that presents a model minimum set of uniform variables or data elements for describing a motor vehicle crash. This uniformity assists transportation safety professionals and governments in making decisions that lead to safety improvements. Similarly, MIRE provides a recommended list of elements to use when reporting road and traffic characteristics, thereby increasing uniformity of road network data. More information on MMUCC and MIRE is presented at the end of this chapter.
Data integration is a measure of whether different databases can be linked together to merge the information in each database into a combined database. Each State maintains its own crash database. However, crash data alone do not typically provide sufficient details on issues like environmental risk factors, driver experience, or medical consequences. Linking crash data to other databases, such as road characteristics, driver licensing, vehicle registration, and hospital outcome data assists analysts and planners in evaluating the relationship of the circumstances of the crash and other factors (e.g., human, road, medical treatment) at the time of the crash. In addition, integrated databases promote collaboration among agencies, which can lead to improvements in the data and the data collection process.
Some data are more challenging to integrate with other data sets. For example, hospital data are difficult to integrate with crash data due to the lack of a common identification system (as well as medical privacy laws). This is different from crash, road characteristics, and volume data, which can share a common referencing system on the road and thus be integrated and linked more easily for analysis.
Spatially-located data in a GIS system can be integrated simply based on spatial position. This geographic integration can assist agencies in bringing together data that were gathered by various departments or agencies that may use different data storage standards and reference systems.
Accessibility is a measure of how easy it is to retrieve and manipulate safety data in a system, in particular by those entities that are not the data system owners. Complete, accurate, and timely data easily made available to localities, MPOs, and other safety partners can greatly enhance transportation planning and safety investments. Agencies or departments who house safety data, especially crash data, should consider how accessible the data are to external parties and how the process of obtaining data could be streamlined.
Local, State, and Federal agencies, as well as non-governmental organizations, require accurate data to be available for analysis and problem solving. Thus, programs to improve data should be in the work programs of all agencies invested in road safety. Data could be improved by changes in policy, technology, assessments, and training.
With so many agencies and organizations involved in the data collection process, published policy is a necessity. A standard set of procedures can provide a clear expectation of each agency’s roles and responsibilities in data collection. Federal guidance and State legislation or administrative policy and regulations generally form a basis for policy. An example of Federal guidance comes from the provision in the MAP-21 transportation legislation that requires States to collect a comprehensive set of roadway and traffic fundamental data elements (FDEs) on all public roads.5
Technology plays an important role in data collection improvement. Federal legislation provides funds that allow States to improve their data collection systems with the latest technology for quality data collection and integration. Technology is not static and is always changing. Some technology examples that help facilitate data collection include electronic crash reporting systems, GPS location devices, barcode or magnetic strip technologies, wireless communications, error checking, and conflicting fields.
Assessments are official evaluations that government agencies conduct to determine the effectiveness of a traffic safety process or program. A team of outside experts conducts a comprehensive assessment of the highway safety program using an organized, objective approach and well-defined procedures that:
Both FHWA and NHTSA provide these types of assessments, such as the Roadway Data Improvement Program (RDIP), which can improve the quality of an agency’s data through expert technical assistance and fresh perspectives. When State agencies request an RDIP assessment, an FHWA team reviews and assesses a State’s roadway data system for the content of the data collected; for the ability to use, manage and share the data; and to offer recommendations for improving the road data. The RDIP also examines the State’s ability to coordinate and exchange road data with local agencies, such as those in cities, counties, and MPOs.6
Education and training of transportation professionals play a vital role in improving data and data collection. For example, law enforcement officers create the crash data that is used by safety professionals to conduct studies and evaluate road safety. Thus, law enforcement need to understand how crash data are used in policy development and investment decisions, infrastructure improvements, and safety planning. Through proper education and training programs, law enforcement can have a broader perspective of their contribution to reducing crashes through improved data reporting. Other examples include training transportation professionals on the latest data collection tools and technology, advising court officials and adjudicators on important changes to safety legislation and penalties, and training personnel on how to handle crash reports with inaccurate or missing information.
The following two sections present examples of Federal guidance that leads State agencies into improving the quality of their safety data.
Statewide motor vehicle traffic crash data systems provide the basic information necessary for effective road safety efforts at any level of government—local, State, or Federal. Unfortunately, the use of State crash data is often hindered by the lack of uniformity between and within States. Data definitions, the number and type of data elements, and the threshold for collecting data varies from jurisdiction to jurisdiction. The Model Minimum Uniform Crash Criteria (MMUCC) was developed to help bring greater uniformity to crash data collection and provide national guidance to data collectors. MMUCC represents a voluntary and collaborative effort to generate uniform, accurate, reliable, and credible crash data to support data-driven highway safety decisions at a State and a national level. MMUCC serves as a foundation for State crash data systems.
The following is the MMUCC format for “Person Data Element Derived from Collected Data.”
PD1. Age
Definition: The age in years of the person involved in the crash
Source: This data element is derived from Date of Birth (P2) and Crash Date and Time (C3).
Attribute:
Rationale: Age is necessary to determine the effectiveness of safety countermeasures appropriate for various age groups.
Since MMUCC is a minimum set of recommended crash data, States and localities may choose to collect additional motor vehicle crash-related data elements if they feel the data are necessary to enhance decision making. Implementation of MMUCC is a collaborative effort involving the Governors Highway Safety Association, FHWA, NHTSA, and the Federal Motor Carrier Safety Administration (FMCSA).
The MMUCC Guideline is updated every four or five years to address emerging highway safety issues, simplify the list of recommended data elements, and clarify definitions of each data element.
MMUCC consists of data elements recommended to be collected by investigators at the crash scene. From the crash scene information, additional data elements can be derived to assist law enforcement. Additional data elements are available through linkage to driver history, hospital and other health/injury data, and road inventory data. Each group of data elements has a unique identifier that describes the type of data element and whether it is derived or linked data.
MMUCC data elements are divided into four major groups that describe various aspects of a crash: crash, vehicle, person, and roadway. Each data element includes a definition, a set of specific attributes, and a rationale for the specific attribute.
For the entire list of MMUCC data elements, refer to the latest edition of the MMUCC Guideline located at https://www.nhtsa.gov/mmucc-1.
The MMUCC data elements represent a core set of data elements. The fourth edition (2012) of the MMUCC Guideline contains 110 data elements and recommends that States collect all 110 data elements. To reduce the data collection burden, MMUCC recommends that law enforcement at the scene should collect 77 of the 110 data elements. From crash scene information, 10 data elements can be derived, while the remaining 23 data elements should be obtained after linkage to other State data files. States unable to link to other State data to obtain the MMUCC linked data elements should collect, at a minimum, those linked data elements feasible for collecting on the crash report. At the same time, States should work to develop data linkage capabilities so they eventually are able to obtain, via linkage, all of the information to be generated by the MMUCC linked data elements.
Critical safety data include not only crash data, but also road inventory data, traffic data, and other information. State DOTs need accurate and detailed data on road characteristics as they develop and implement strategic highway safety plan (SHSPs) and look toward making more data driven safety investments.
With the need for and availability of so many types of data, the question becomes “How can transportation agencies be sure that they are collecting the necessary roadway data to make effective road safety decisions?” MIRE is a vitally important resource that defines the data needed to help transportation agencies build a road characteristics database that will lead to good safety analysis. MIRE defines 202 individual characteristics of the road system that should be collected. These characteristics are referred to as data elements. The elements fall into three broad categories:
Most State and local transportation agencies do not have all the data needed to use analysis tools such as SafetyAnalyst, the Interactive Highway Safety Design Model, and other tools and procedures identified in the Highway Safety Manual. MIRE provides a structure for road inventory data that allows State and local transportation agencies to use these analysis tools with their own data rather than relying on default values that may not reflect local conditions.
As the need for road inventory information has increased, new and more efficient technologies to collect road characteristics have emerged. However, the collected data need a framework for common information sharing. Just as MMUCC provides guidance for consistent crash data elements, MIRE provides a structure for roadway inventory data elements using consistent definitions and attributes. It defines each element, provides a list of attributes for coding, and assigns a priority status rating of “critical” or “value added” based on the element’s importance for use in analytic tools, such as SafetyAnalyst.
The latest version of MIRE can be viewed and downloaded from the FHWA Office of Safety site, https://safety.fhwa.dot.gov/tools/data_tools/mirereport//.
Figure 3-5 displays a breakdown of the major data element categories and subcategories contained in MIRE. MIRE further breaks down each subcategory into individual data elements. For a complete listing of MIRE data elements, refer to the MIRE publication.
While the complete list of MIRE elements is rather extensive, there are a basic set of elements within MIRE called the Fundamental Data Elements (FDE) that an agency needs to conduct safety analyses regardless of the specific analysis tools used or methods applied. As discussed, the need for improved and more robust safety data is increasing due to the development of a new generation of safety data analysis tools and methods.
The types of road safety data presented in this unit are only useful as much as they are capable of being linked through a common geospatial relational location referencing system. States recognize that they must have a common relational location referencing system (i.e., geographic information system or linear referencing system) for all public roads if they are going to integrate different types of safety data. If all safety data are referenced to the same system, the road characteristics data can be linked with the crash data, which would permit the State to identify locations on all public roads where crash patterns are occurring that can be reduced through known countermeasures.
In most States, development of a common referencing system for all public roads will require significant effort and cooperation with local agencies. The Federal Highway Performance Monitoring System requires GIS-based referencing for all roads in the Federal-aid highway system, interstate highways, and public roads not classified as local roads or rural minor collectors. However, significant travel occurs on local roads and rural minor collectors.7 Some local agencies have or are developing, their own GIS-based referencing systems for roads in their inventory data. Light detection and ranging (LIDAR) systems are often used to accurately survey the road network. The State should work with local agencies to incorporate these referencing systems into the State base map. Once the referencing systems are combined, attribute data for additional mileage can be added when either State or local agencies develop or expand inventories. Moreover, as stated above, this will lead to the ability to link crashes with inventory and traffic data, enabling the State to use the more advanced problem identification methods on more and more miles of public roads.
Data are crucial to improving road safety. Safety data consist of various kinds of data that can be used to identify safety problems and priorities so that safety partners in many agencies can address important issues. Data such as crash data, traffic volume data, and road characteristics data are often used and are critical for safety analysis by many agencies. Other data, such as conflict observations, emergency medical data, and citation data, can be useful in a supplemental role for specific studies. Regardless of the type of safety data, the quality of the data is vitally important. Agencies that collect safety data should strive to improve their timeliness, accuracy, completeness, uniformity, integration, and accessibility to maximize their potential to drive good decisions.
Given the scenario you selected above, how do you think the availability of other types of data could affect your recommendations? Such data may include any of the data types covered in Chapter 3.2. (e.g., EMS and hospital injury data, enforcement citations, public complaints, or other data). What additional information could this reveal?
RSPCB Program Point of Contact
Felix Delgado, FHWA Office of Safety
Felix.Delgado@dot.gov
FHWA Office of Safety
Staff and Primary Work Responsibilities
FHWA Office of Safety
Safety and Design Team
FHWA Resource Center